Generative Ground Truth
MFMs synthesize HQ targets from real LQ images—scalable paired data without physical capture.
Real-world LQ–HQ pairs from MFMs to expand IR generalization boundaries.
The Hong Kong Polytechnic University · OPPO Research Institute
* Equal contribution · † Corresponding author


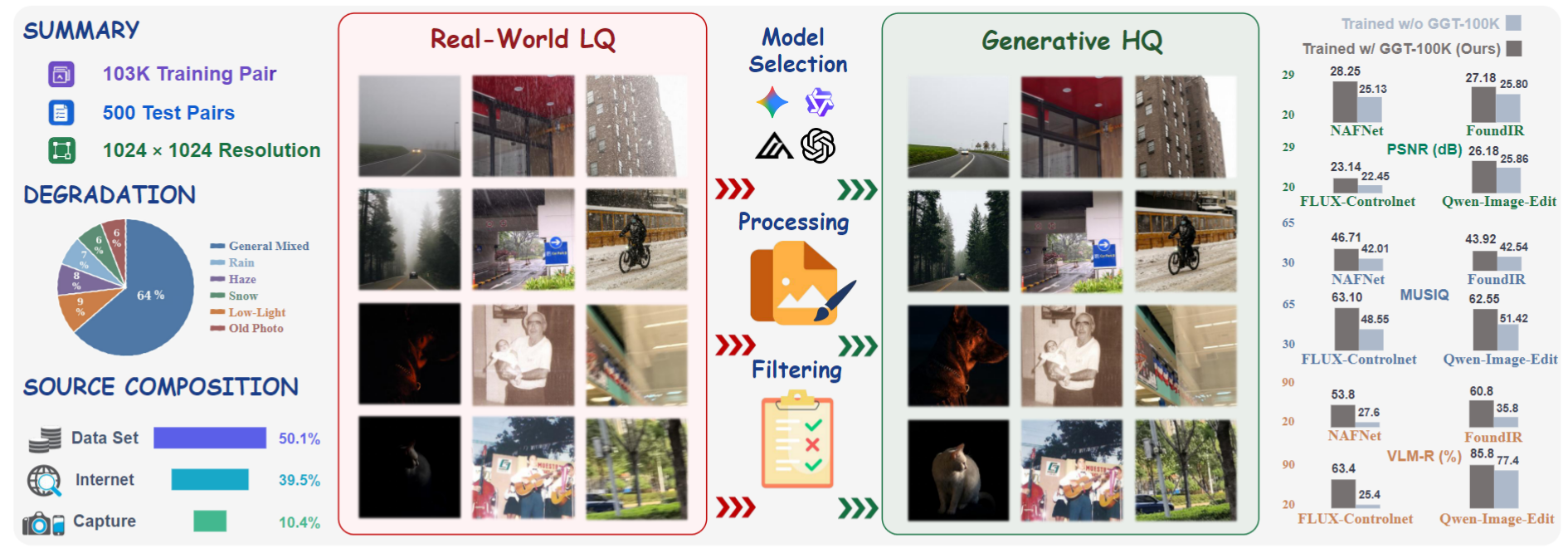

Highlights
MFMs synthesize HQ targets from real LQ images—scalable paired data without physical capture.
GGT-100K covers six degradation categories, plus a curated 500-pair test set. Each category contains complex mixed degradations.
9 MFMs evaluated → Nano-Banana-2 selected → metric + VLM + manual quality control.
Consistent improvements on 10 baselines; largest gains on generative IR models.
Abstract
Real-world image restoration (IR) is bottlenecked by the scarcity of high-quality paired training data. Synthetic datasets are abundant but often fail to model real-world degradations, while real-world paired datasets are expensive and difficult to capture. As a result, IR models trained on these datasets show limited generalization in real-world scenarios. In this work, we propose Generative Ground Truth (GGT) by using generative multimodal foundation models (MFMs) to produce high-quality (HQ) targets from real-world low-quality (LQ) images. We first conduct a systematic evaluation of nine state-of-the-art MFMs, including Nano-Banana-2 and GPT-Image-2, on images of various scenes and degradation types. The results demonstrate that Nano-Banana-2 with VLM-based adaptive prompting shows the highest capability to synthesize perceptually realistic and content-faithful HQ targets, which can serve as the GGT for the LQ input. We then employ Nano-Banana-2 to build a GGT synthesis pipeline with multi-stage quality control and construct GGT-100K, an LQ-HQ paired dataset comprising 103,707 training pairs and covering diverse scenes and complex real-world degradations. A test set of 500 image pairs is also established. Extensive experiments show that GGT-100K consistently improves the real-world generalization of a wide range of IR models, with particularly strong benefits for finetuning generative models for IR tasks.
Keywords: Generalizable image restoration · Generative ground truth · Multimodal foundation models
Dataset
A large-scale real-world LQ–HQ dataset built with generative MFMs, designed as a complementary source to existing data—not a replacement.
These categories are not isolated single-degradation settings; each category contains complex mixed degradations. For example, rain images usually include rain together with blur, noise, and compression artifacts. Test pairs are manually verified for fidelity and minimal hallucination.
License: CC BY-NC-ND 4.0
Method
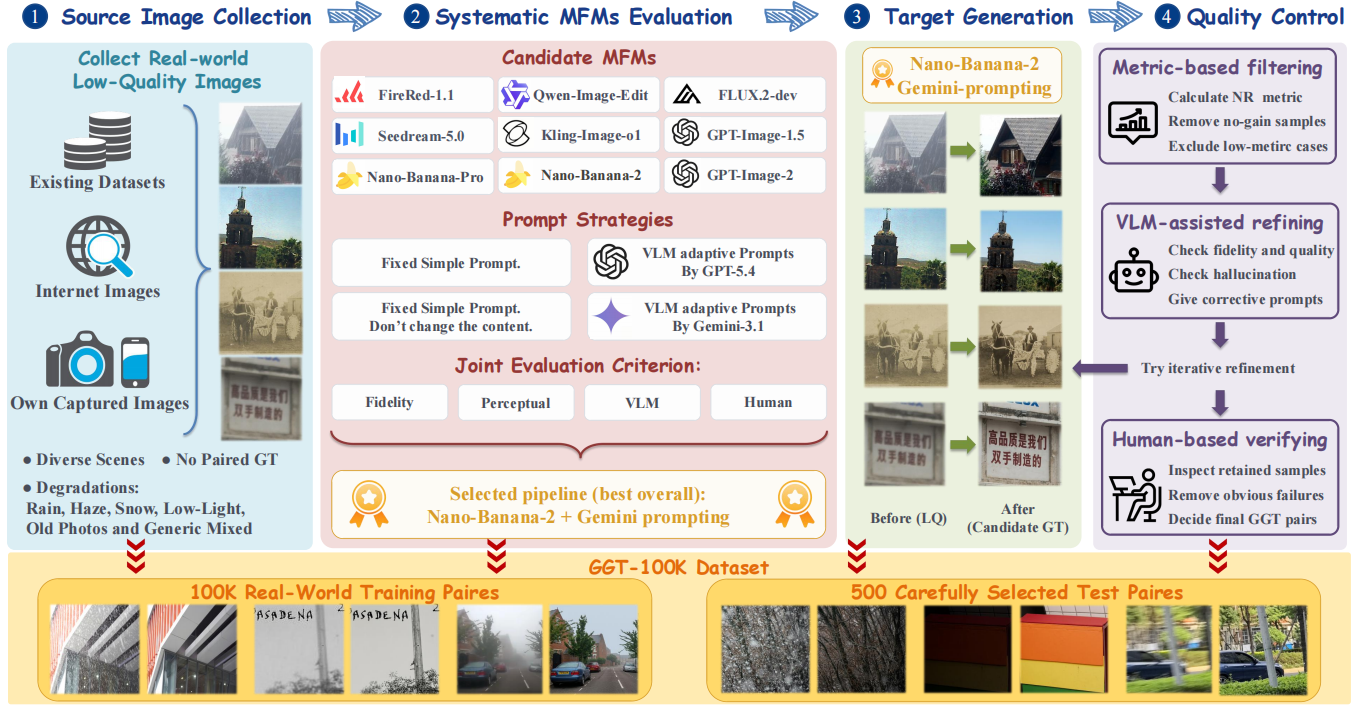
Real-world LQ images without HQ references, from three sources:
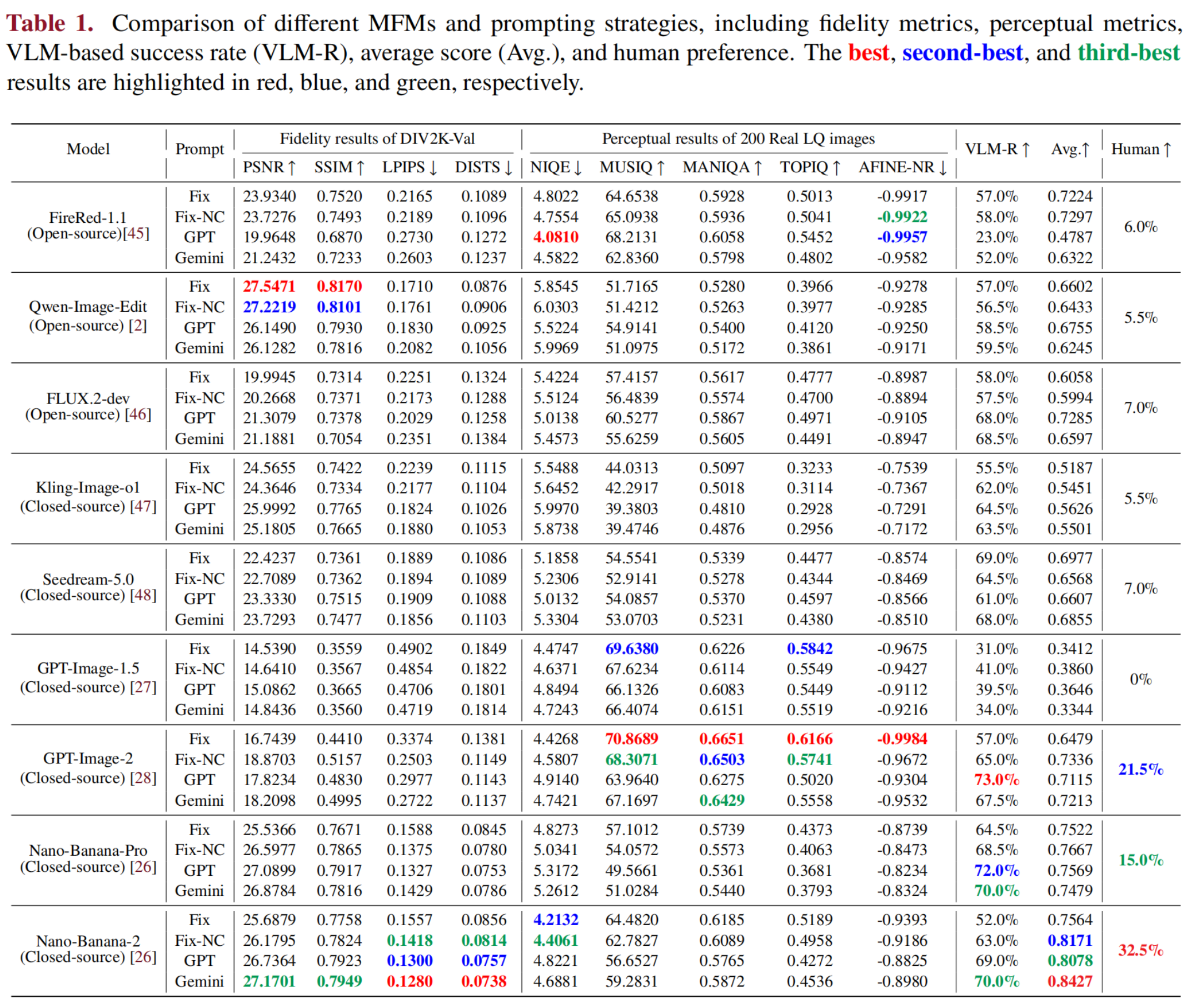
9 MFMs × fixed / adaptive prompts. Evaluated on fidelity (DIV2K-Val), perceptual quality (200 real LQ), VLM-R, and human preference.
Selected: Nano-Banana-2 + Gemini adaptive prompting (best Avg. 0.84, human pref. 32.5%).
Experiments
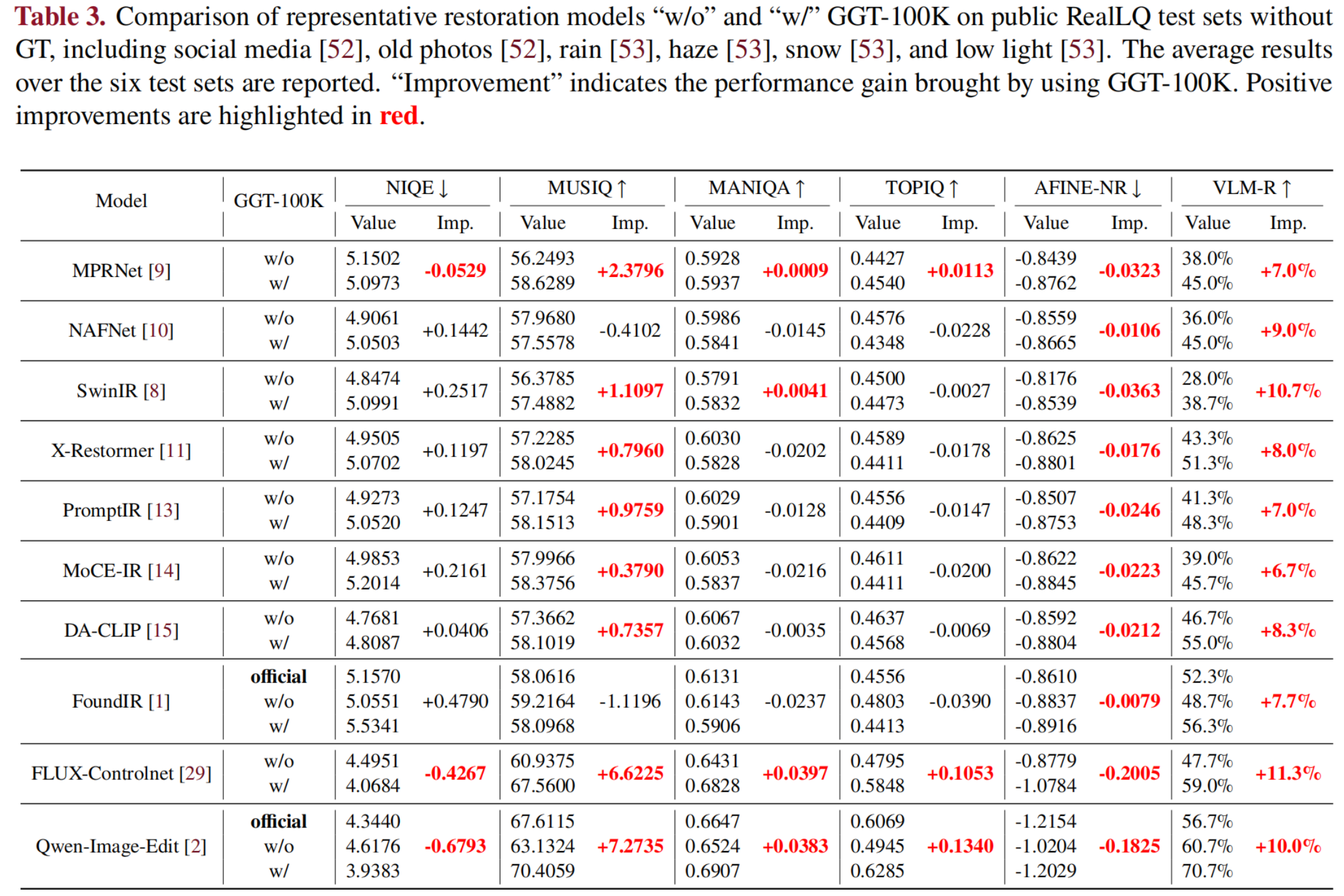
10 models trained w/o vs. w/ GGT-100K (1:1 sampling with 200K existing pairs).
GGT-100K improves fidelity, perceptual metrics, and VLM-R across all models; generative models benefit most.


Similar trends on RealDeg and OpenReal80K—consistent AFINE-NR and VLM-R gains, especially for generative IR.
BibTeX
@article{kong2026GGT-100K,
title={GGT-100K: Generative Ground Truth for Generalizable Real-World Image Restoration},
author={Kong, Xiangtao and Zhao, Jixin and Sun, Lingchen and Wu, Rongyuan and Zhang, Lei},
journal={arXiv preprint arXiv:2605.31039},
year={2026}
}